Hi there!
After posting the previous article, I've got lots of emails asking to show and prove how one solution is better than another.
I enthusiastically got down to comparisons, but it's all usually a little bit trickier than at first sight.
Yes, in this article I suggest taking out and measuring all the parsers!
Let's get started!
Before comparing anything, we've got to figure out: what are we really going to compare?! HTML parsers, but what is it?
An HTML parser is:
- Tokenizer — breaking text down into tokens
- Tree Builder — placing tokens in “correct positions” in a tree
- Tree follow-up
Someone out of the blue might say: “There's no need to build a tree for HTML parsing, it's enough to get tokens.” Unfortunately, they're wrong.
Actually, for correct HTML tokenization, we should have a tree at hand. Points 1 and 2 go as one.
Here're 2 examples:
Example 1:
<svg><desc><math><style><a>The result of correct processing:
<html>
<head>
<body>
<svg:svg>
<desc:svg>
<math:math>
<style:math>
<a:math>Example 2:
<svg><desc><style><a>The result of correct processing:
<html>
<head>
<body>
<svg:svg>
<desc:svg>
<style>
<-text>: <a>After “:” comes namespace, if unspecified then html.
As the examples show, the STYLE element behaves differently — depending on its position. The 1st variant has the element A, while in the 2nd it's already a text element. Here I can give examples with “frameset”, “script”, “title”... and their different behavior, but I guess you have the general idea.
Now we can draw a conclusion that breakdown into tokens can't be correctly done without building an HTML tree. Consequently, HTML parsing can't be done without at least 2 stages: tokenization and tree building.
As to the terms: “strict”, “failing the spec”, “light”, “HTML 4”, and the like... I'm sure one can safely replace all these terms with 1: “doesn't process correctly.” It's all absurd.
How and What to Compare?
Here comes the point. An HTML parser is too proud a name for everything. Moreover, even those dubbed HTML tokenizers aren't actually such.
With all the parsers at hand, I wonder what and with what to compare? So let's compare true parsers:
MyHTML, HTML5Lib, HTML5Ever, Gumbo.
It's them that comply with the latest spec, and their result will match what we can see in present-day browsers.
Untrue parsers (failing the spec) may greatly vary in speed / memory, but it's a fat lot of use since they process a document incorrectly.
No runarounds like “a parser for HTML 4” will count. Things always change, and we've got to keep pace with them.
I should say HTML5Ever isn't an absolutely true parser. Authors write it doesn't pass all html5lin-test-tree-builder tests for correct tree building. It became true for its efforts.
At the moment of writing this article, HTML5Lib wasn't building the tree for some HTML formats correctly. But it's all bugs the authors will hopefully fix.
Let's measure time/memory for 466 HTML files by Alexa TOP500. 466, not 500, because not all websites are running or open their content.
For each page, a fork will be made with the stages:
- Complete parser initialization
- 1 page parsing
- Resource deallocation
There'll also be an ex vivo test — running all the pages with 1 object, where possible. Everything will occur sequentially.
Down to the tests!
The following have been qualified for our tests: MyHTML, HTML5Ever, Gumbo.
Sadly, HTML5Lib failed testing. A prerun proved it's much slower than the others. There's no use comparing it — it's written on Python and is very, very slow.
MyHTML and Gumbo are written on C. HTML5Ever — it’s Rust. I'm not good in Rust, not yet, so I asked Alexey Voznyuk to help me. Alexey agreed (kudos to him!) and made a C wrapper for parser testing.
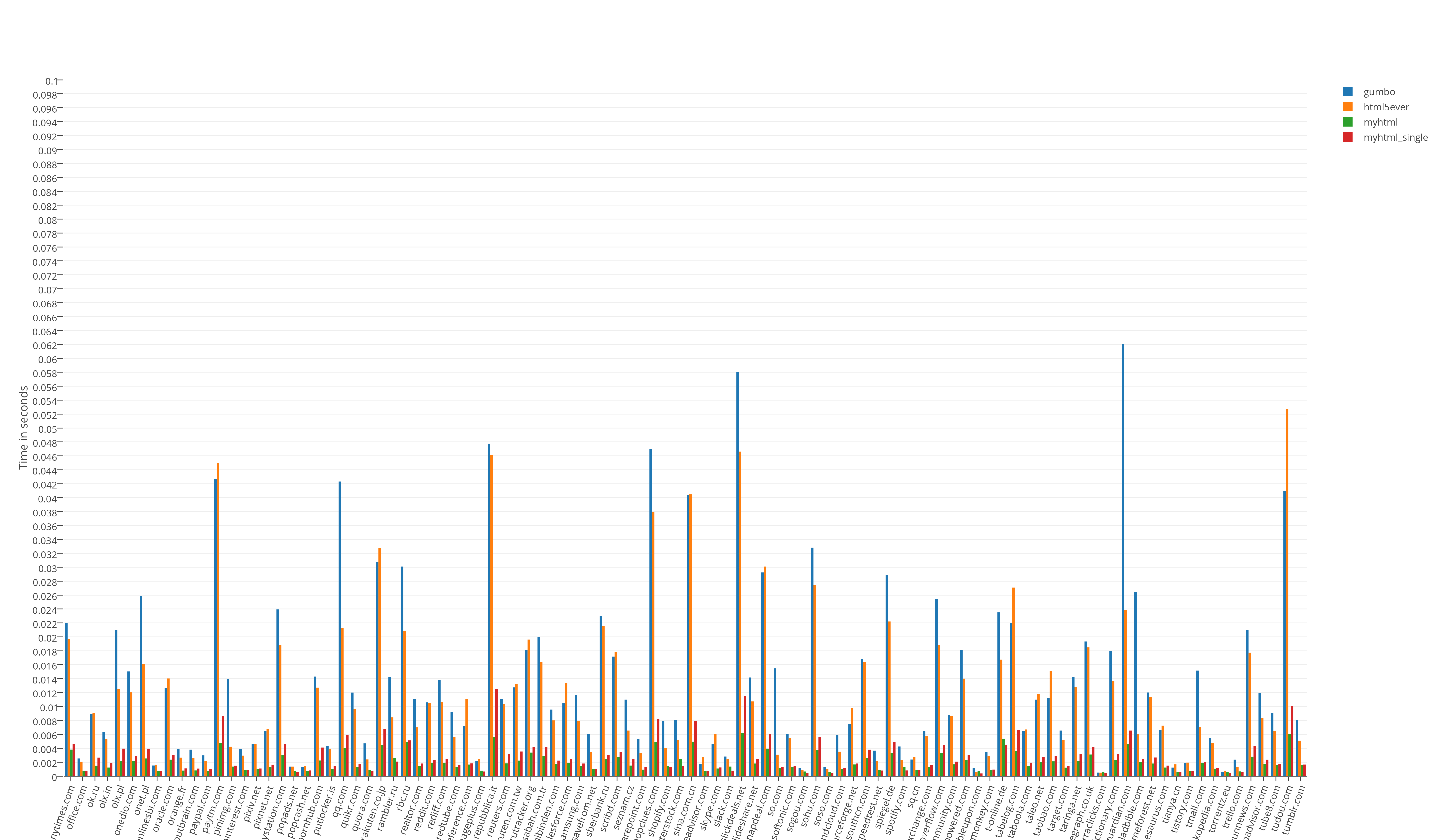
Runtime test results:
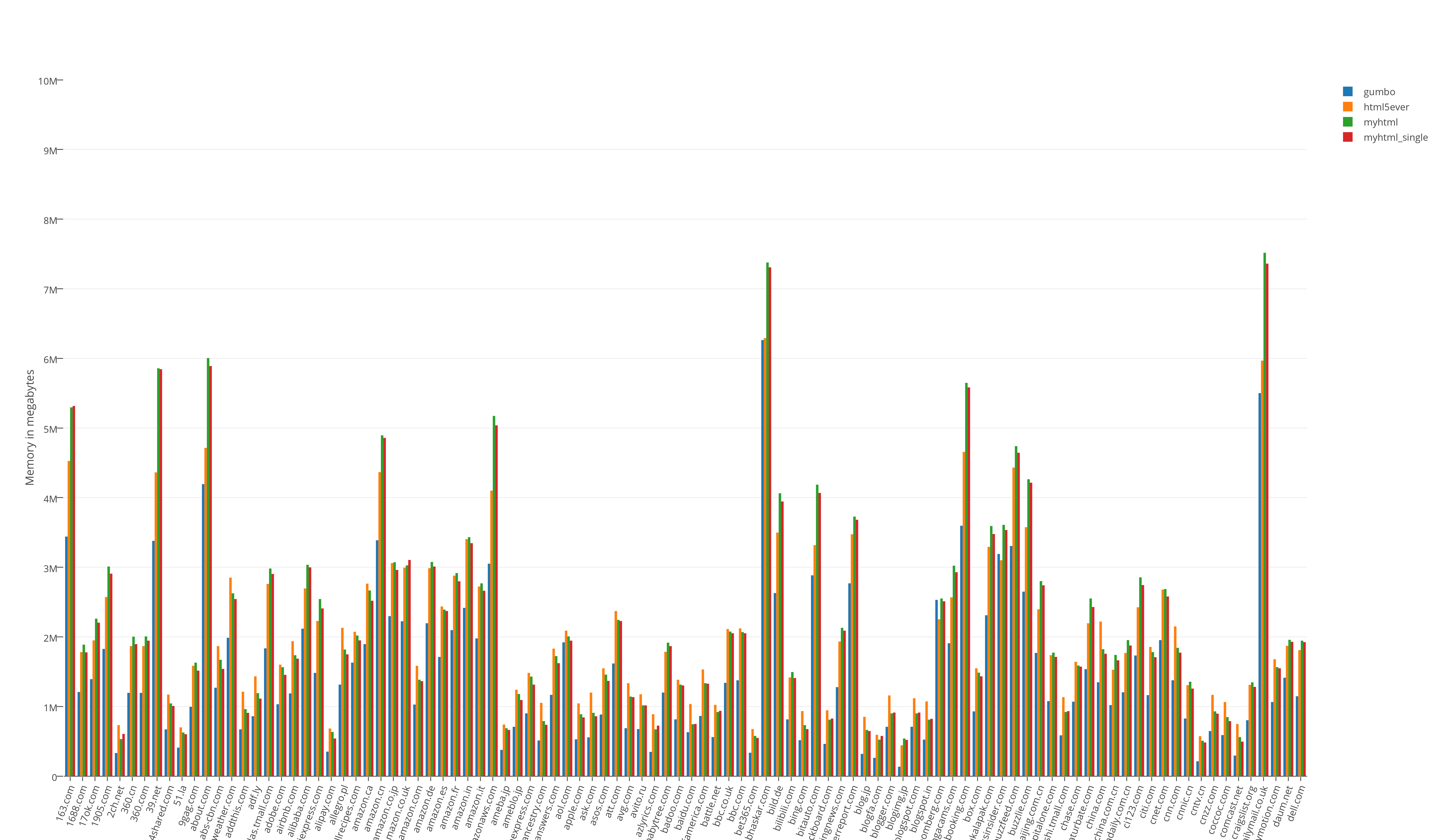
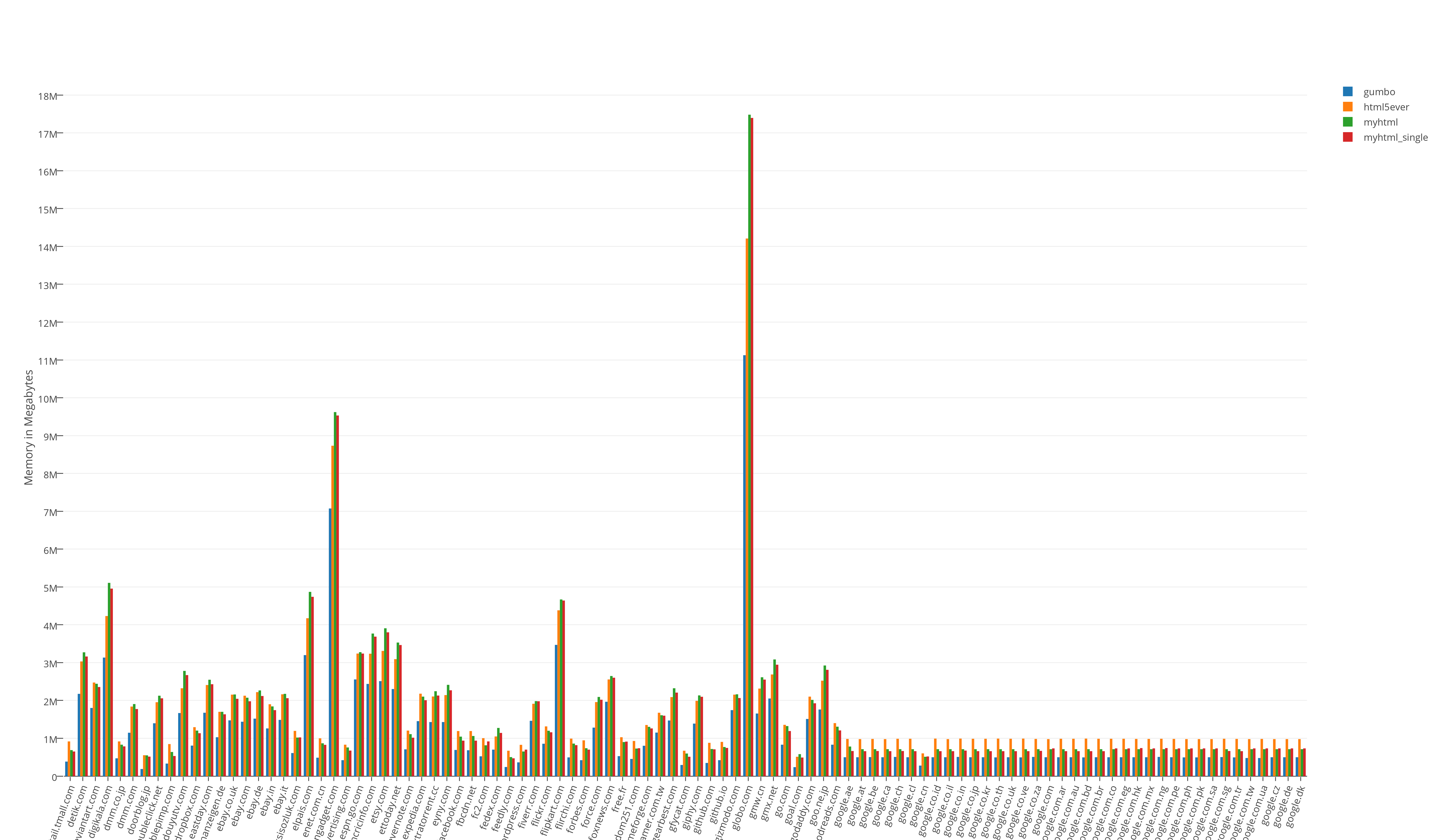
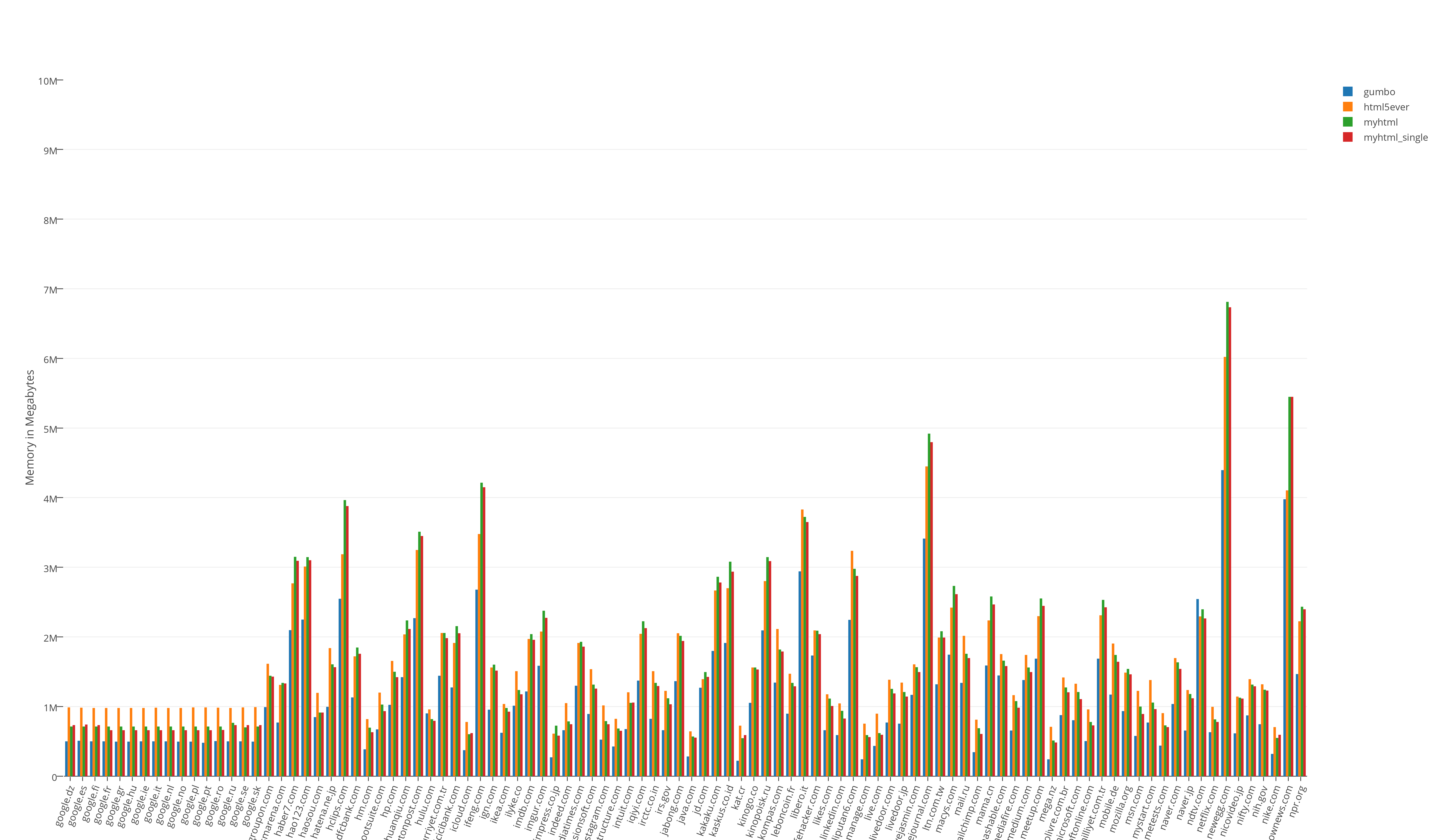
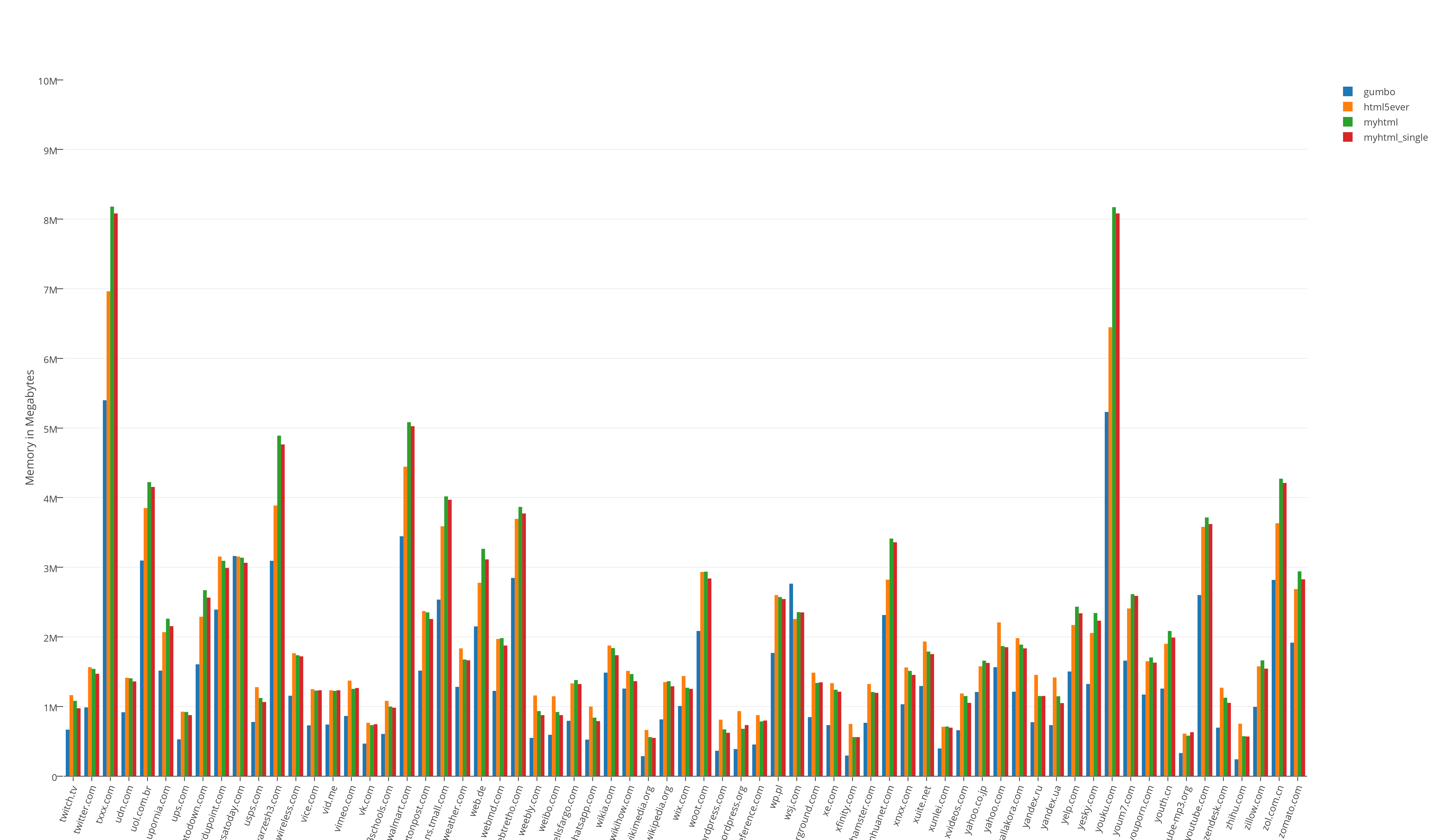
Resource consumption test results:
Runtime test results divided by 100

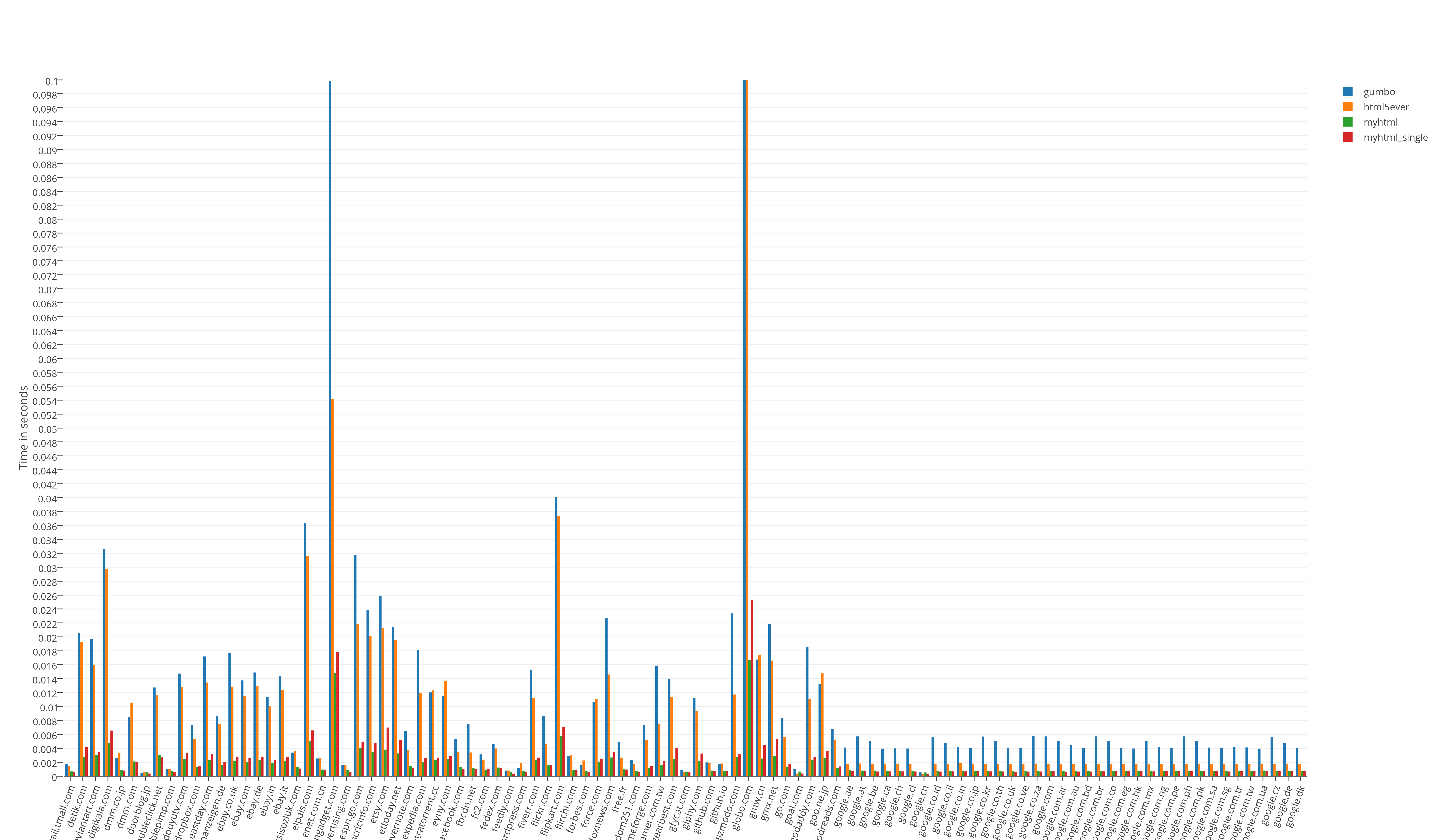
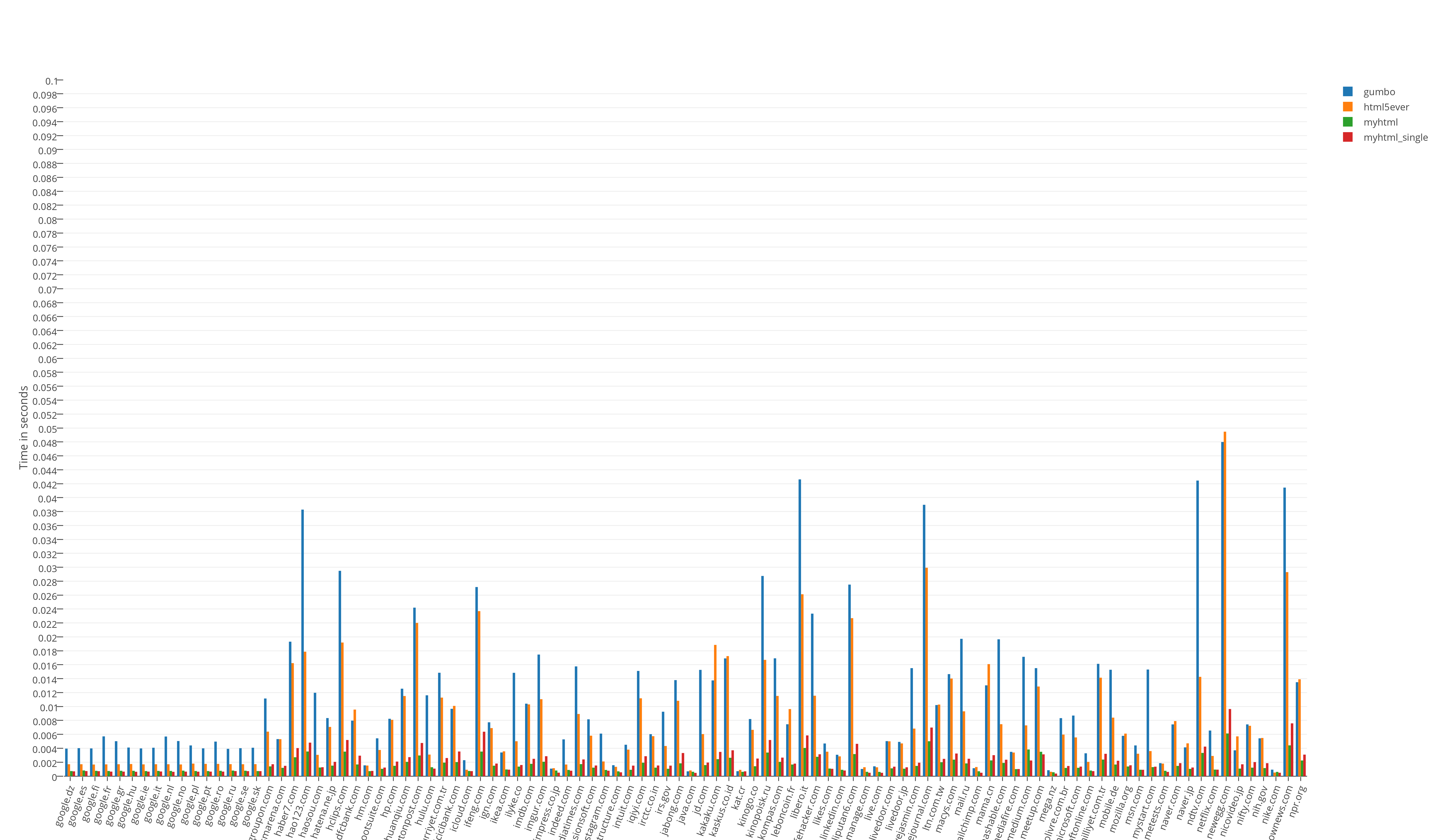

Resource consumption results divided by 100

Ex vivo test result. Running all (466) pages in 1 process:
MyHTML:
Overall time: 0.50890;
Memory at the beginning: 1052672;
Memory at the end: 32120832
MyHTML Single Mode:
Overall time: 0.72160;
Memory at the beginning: 1052672;
Memory at the end: 31805440
Gumbo:
Overall time: 6.12951;
Memory at the beginning: 1052672;
Memory at the end: 29319168
HTML5Ever:
Overall time: 4.50536;
Memory at the beginning: 1052672;
Memory at the end: 30715904
UPDATE:
libhubbub:
Overall time: 2.23302;
Memory at the beginning: 1110016;
Memory at the end: 13430784
libhubbub && libdom:
Overall time: 7.10649;
Memory at the beginning: 1110016;
Memory at the end: 804683776
Totals
The undisputed leader in speed is MyHTML. Gumbo is the memory leader, not surprisingly. HTML5Ever has fallen flat, to put it mildly. The latter was neither quick nor good in memory, it can be used only on Rust.
The ex vivo test has shown little differences in memory, although really gigantic ones in speed.
Things used
Hardware:
- Intel® Core(TM) i7-3615QM CPU @ 2.30GHz
- 8 Gb 1600 MHz DDR3
Software:
- Darwin MBP-Alexander 15.3.0 Darwin Kernel Version 15.3.0: Thu Dec 10 18:40:58 PST 2015; root:xnu-3248.30.4~1/RELEASE_X86_64 x86_64
- Apple LLVM version 7.0.2 (clang-700.1.81)
- Target: x86_64-apple-darwin15.3.0
- Thread model: posix
Links
Benchmark code
Images and CSV
MyHTML, Gumbo, HTML5Ever
API for HTML5Event by Alexey
Thanks for reading!
P.S. by MyHTML's author
As MyHTML's author, I found it morally hard doing such testing. However, I tried to deal with the matter with greatest responsibility and treat each parser as my own.