Hi, there!
As you might have guessed from the title, today's topic is HTML parsing.
Preface
Once I got an X idea, but its implementation required a calculated DOM with all its styles and goodies. Googling retrieved nothing useful. There are all kinds of bindings for WebKit, but they work not on all platforms, being very crippled to boot. In some projects, WebKit is wrapped in a frontend you work with via JavaScript. Something was tried out — with a poor outcome though. Resource consumption alone required a lot.
Wants and Wishes
What was wanted didn't seemed much:
- HTML renderer without super dependencies. Only a renderer, without the network layer. In other words, complete HTML computation till drawing in a window
- Ability to fit the envelop to a JavaScript engine
- Ability to easily make bindings for other programming languages
And so I joined the unequal battle!
I studied existing HTML and CSS parsers. They all fell into 3 conventional categories:
- Those parsing at random, with their own approach to HTML tokenization
- Those parsing somehow under specs
- Those parsing strictly under specs
Given No. 3, the subject seems to be dropped, doesn't it?! Nope, and here's why: all existing parsers are made on the principle 'Parse and Die'. It's when you give the program complete HTML, the program returns a result, but all subsequent manipulations except reading are impossible. This fact limits the operation of parsers. Remarkably, some push operating DOM off a level up. Here's the principle: we parse with a C parser and then — via bindings — try to work with DOM on, say, Python, which is a bit absurd.
Further on, nobody allowed for wedging into the thread (HTML meant here) during parsing. This is critical for fitting a JavaScript engine. It's a long story — I'd better show:
HTML document fragment:<script>document.write("<div cl");</script>ass="future"></div><div class="future"></div>So, a fully featured DIV element will come out. By the way, SCRIPT tag tokenization is a hell of an effort. I had to draw a graph.
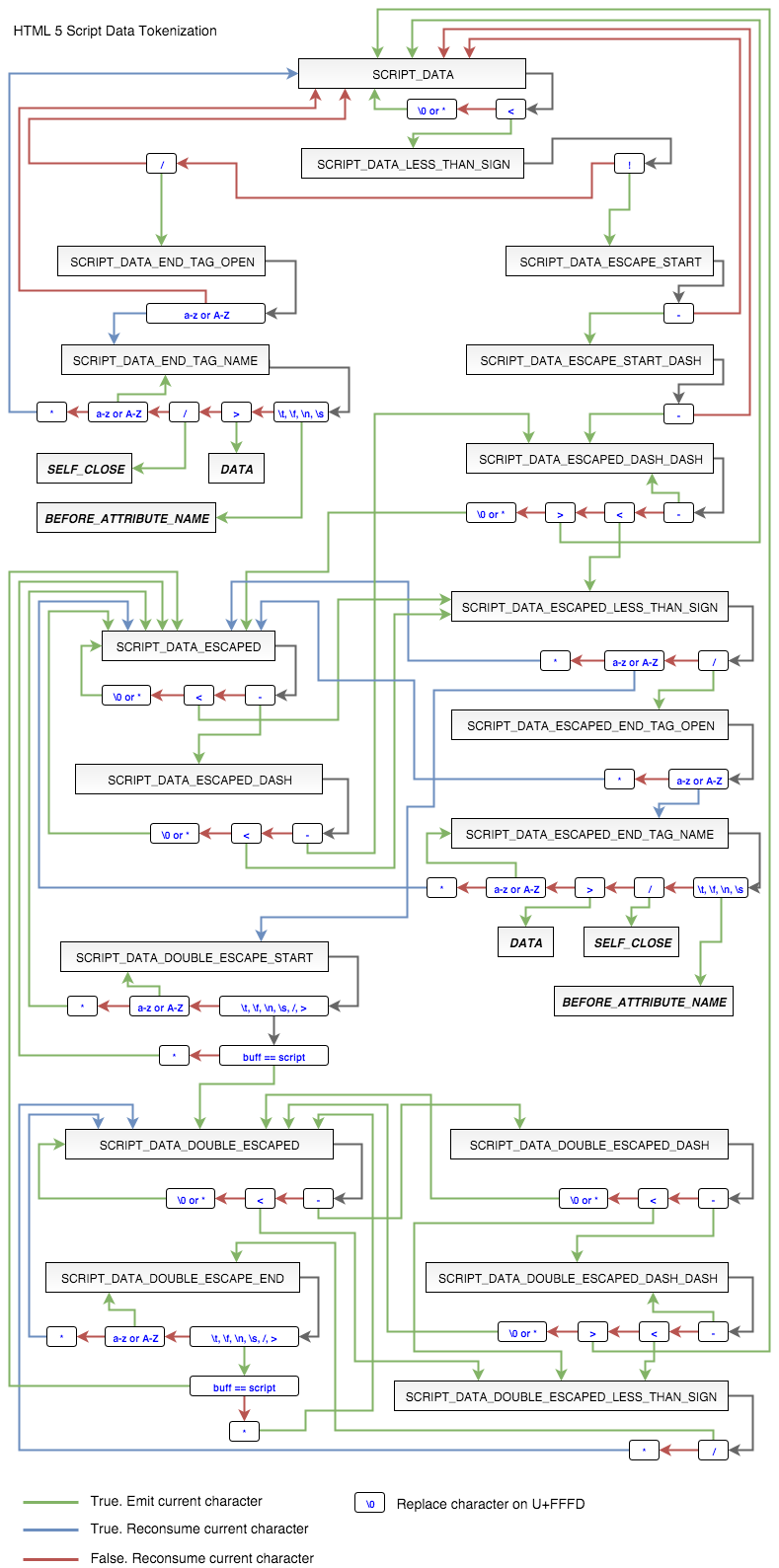
After all that had been seen, the decision was to code from scratch on C. And requirements to code appeared at once:
- C99 support
- Capability to separate the HTML parser from the renderer, to be used standalone
- No external dependencies
Why so tough — on C?! The solution had to be embedded so as to enable relatively easy framing for an external programming language.
Here's what was managed to be drafted hit and miss:
- HTML parser
- CSS parser
- Selectors
- Renderer of 'inline', 'inline-block', 'block', 'table'...
The renderer may deserve a long description, as the short phrase 'Renderer of inline elements' conceals a lot: handling fonts under specs, calculating text size, computing 'vertical-align', building an auxiliary tree to draw text and a whole lot more.
As a result of 2–3 years of unhurried development, I started rewriting the draft copy into a production version. The first was — quite logically — the HTML parser.
Now it has the following capabilities:
- Parsing HTML asynchronously, processing tokens, building the tree
- Full HTML 5 support under specs html.spec.whatwg.org/multipage
- Having 2 APIs: high and low-level. The former is a public API having a description and everything it should, but unable to see structures. The latter is using sources directly
- Ability to manipulate elements: addition, removal, modification
- Ability to manipulate element attributes: addition, removal, modification
- Support of 34 input encodings. Output and all internal work is in UTF-8 only
- Ability to define text encoding Unicode now available: UTF-8, UTF-16LE, UTF-16BE (+ definition by BOM), and Russian ones: windows-1251, koi8-r, iso-8859-5, x-mac-Cyrillic, ibm866
- Ability to run in single mode — without threads
- Parsing HTML fragments
- Parsing chunks. Parsing HTML cuts (broken in arbitrary places) without prebuffering
- No external dependencies
- C99 support
- Passes all tree construction tests from html5lib-tests
- Advanced memory management. Memory is cashed, allocated in chunks and for objects. For example, removing 10 elements and then adding other 10 won't eat away memory for the new ones
- + a whole lot more small but useful features to be described for long.
Next in turn are the CSS parser and Renderer. I'm writing them all by myself, still full of energy.
Any help is very welcome!
Thanks for attention! Hope you'll enjoy it!